【Kubernetes】Numaflow でストリーミング処理を行う¶
Numaflow とは¶
Numaflow は、Kubernetes 上で大規模な並列ストリーム処理を実現するフレームワーク。パイプラインは Kubernetes カスタムリソースとして定義され、Source、処理(UDF)、Sink の各 Vertex で構成される。Argo Workflows のように YAML でパイプラインを記述可能。
利用シーン¶
- リアルタイムデータ分析アプリケーション
- 異常検出、モニタリング、アラートなどのイベント駆動型アプリケーション
- データ計測・転送などのストリーミングアプリケーション
- ストリーミング方式で実行されるワークフロー
特徴¶
- Kubernetes ネイティブ: Kubernetes の知識を活かせる
- 言語非依存: 任意のプログラミング言語を使用可能
- Exactly-once セマンティクス(ニアリアルタイムデータソースの場合): Pod の再スケジュール/再起動によるデータ損失や重複なし
- バックプレッシャー対応の自動スケーリング: 各 Vertex は必要に応じてゼロからスケール
データの整合性保証¶
- At-least-once 配信
- ニアリアルタイムデータソースに対しては Exactly-once セマンティクスを提供
用語¶
パイプライン¶
データ処理ジョブを定義。Vertex(データ処理タスク)と Edge(Vertex 間の関係)のリストで構成。Edge は 1 つの Vertex から複数へ、また v0.10 以降は Join/Cycle により多対一の関係も定義可能。
| pipeline.yaml | |
|---|---|
| pipelineの情報取得 | |
|---|---|
Vertex¶
パイプラインの構成要素。データ処理タスクを担う。
| vertexの情報取得 | |
|---|---|
Vertex Types¶
- Source: データ入力
- Sink: データ出力
- UDF (User Defined Function): データ処理ロジック
Source¶
データソースから Numaflow へデータを読み込む。データ変換/フォーマット、Watermark 追跡、遅延データ検出等を行う。
次のような Source vertex がある。
- Kafka
- HTTP
- Ticker
- Nats
- User Defined Source
User Defined Source とは、プラットフォーム内蔵の source ではサポートされていないシステムからデータを読み込む必要がある場合に、ユーザーが Numaflow SDK を使って書き込むカスタム source のこと。 User Defined Source は、正確に一度だけ読み取るための custom acknowledge 管理もサポートしている。
Sink¶
Sink は処理済みデータの出力先。データベース、データウェアハウス、可視化ツール、アラートシステムなどがある。 source vertex とは異なり、パイプラインには複数の sink vertex を設定できる。
次のような Sink vertex がある。
- Kafka
- Log
- Black Hole
- User Defined Sink
User Defined Sink とは、Numaflow SDK を使ってユーザーが作成できるカスタム sink のことで、処理したデータをシステムに出力したり、プラットフォーム内蔵の sink ではサポートされていない変換を行う必要がある場合に使用する。例えば、入力メッセージを処理した後、Elasticsearch を User Defined Sink として使用することで、処理したデータを保存し、データの検索や分析を行うことができる。
UDF(User Defined Functions)¶
pipeline は、source、sink、UDF(User Defined Functions)という複数の Vertex から構成される。
ユーザー定義関数(UDF)は、ユーザー定義のデータ変換ロジックを実行する Vertex。UDF でのデータ処理はべき等である。 UDF は Vertex Pod のサイドカーコンテナとして実行され、受信したデータを処理する。 メイン・コンテナ(プラットフォーム・コード)とサイドカー・コンテナ(ユーザー・コード)間の通信は、Unix Domain Socket 上の gRPC を介して行われる。
ユーザーが実行できる処理には次の 2 種類がある。
- map
- reduce
map の例¶
公式が偶奇の判定を行う[例]を紹介している。パイプラインの概要は図の通り。
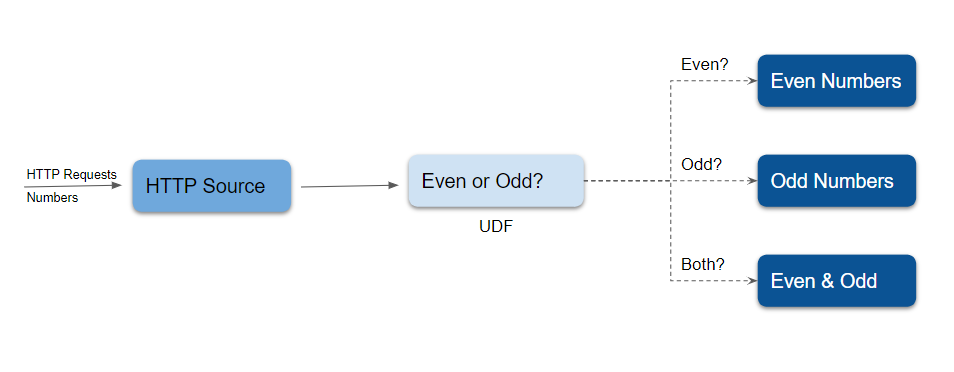
これを yaml で表すと次のようになる。condition はタグを指定して、そのタグが付いたデータのみを処理するように指定している。
この UDF の実装はこちら
Auto Scaling¶
Numaflow は、Horizontal Pod Autoscaling と Vertical Pod Autoscaling の両方で scale out/in できる。
Horizontal Pod Autoscaling¶
Numaflow でサポートされている Horizontal Pod Autoscaling には次のようなものがある。
- Numaflow Autoscaling
- Kubernetes HPA
- Third-party Autoscaling(KEDA など)
Numaflow Autoscaling¶
Numaflow は 0 から N までのオートスケーリング機能を提供しており、すべての UDF、sink、source vertex で利用可能。
Joins and Cycles¶
Joins¶
Numaflow では、複数の Vertex から 1 つの Vertex にメッセージを転送できる。これは、Join と呼ばれる。 Join Vertex の導入により、ユーザーはパイプラインの冗長性を排除できる。多対一のデータフローをサポートし、同じジョブを実行する複数の Vertex を必要としない。
join を用いたパイプラインの例を 2 つ示す。
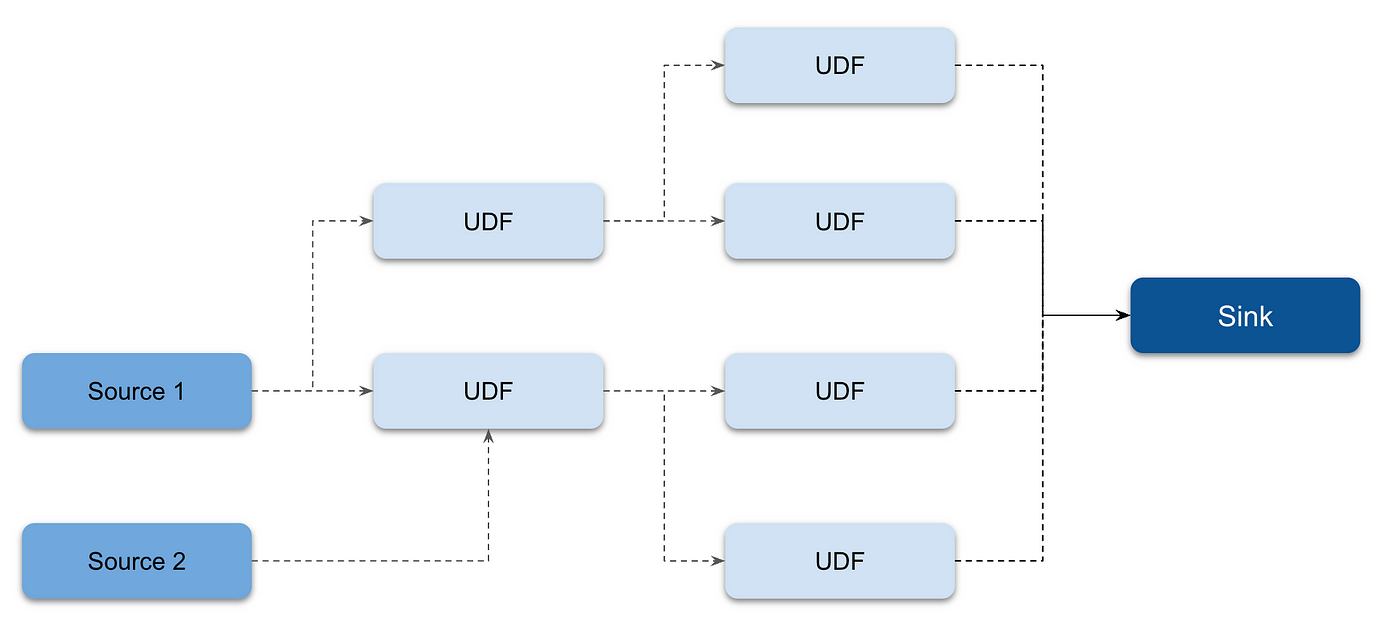
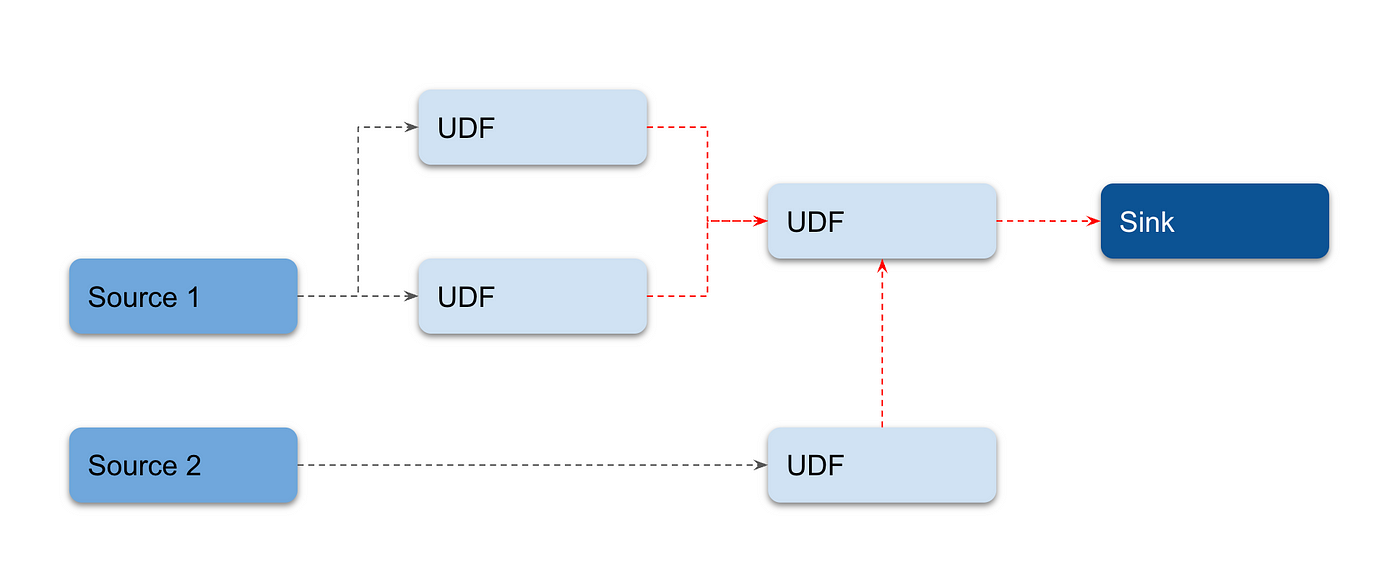
Cycles¶
Numaflow では、Vertex 間に循環を作成できる。これは、Cycle と呼ばれる。
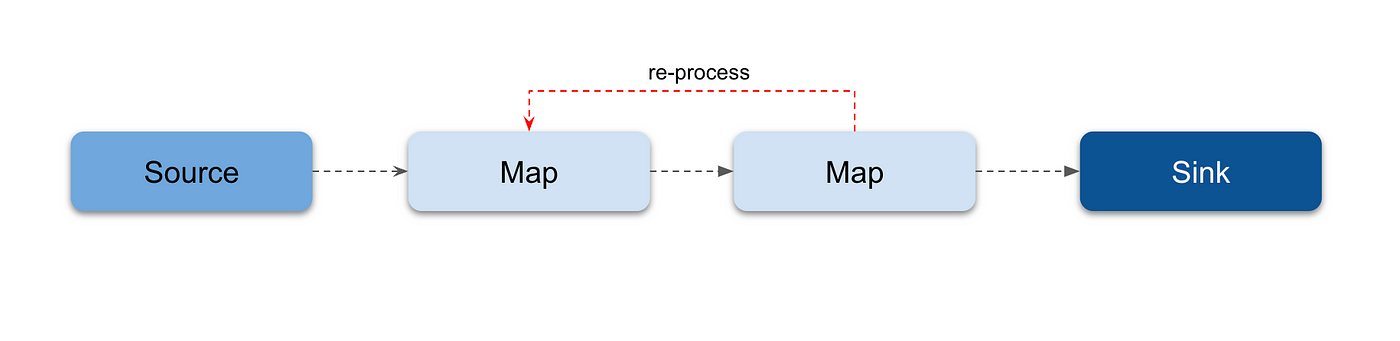
Quick Start を試す¶
公式のドキュメントを参考に、Quick Start を進めてみた。 GKE Autopilot のクラスタを作成し、ドキュメントに従って各リソースを作成する。
次のコマンドを実行して、https://localhost:8080/にアクセスすると、Numaflow の UI が表示される。 (補足: Cloud Shell で実行するとうまくできなかったので、開発マシンからコマンド実行した。)
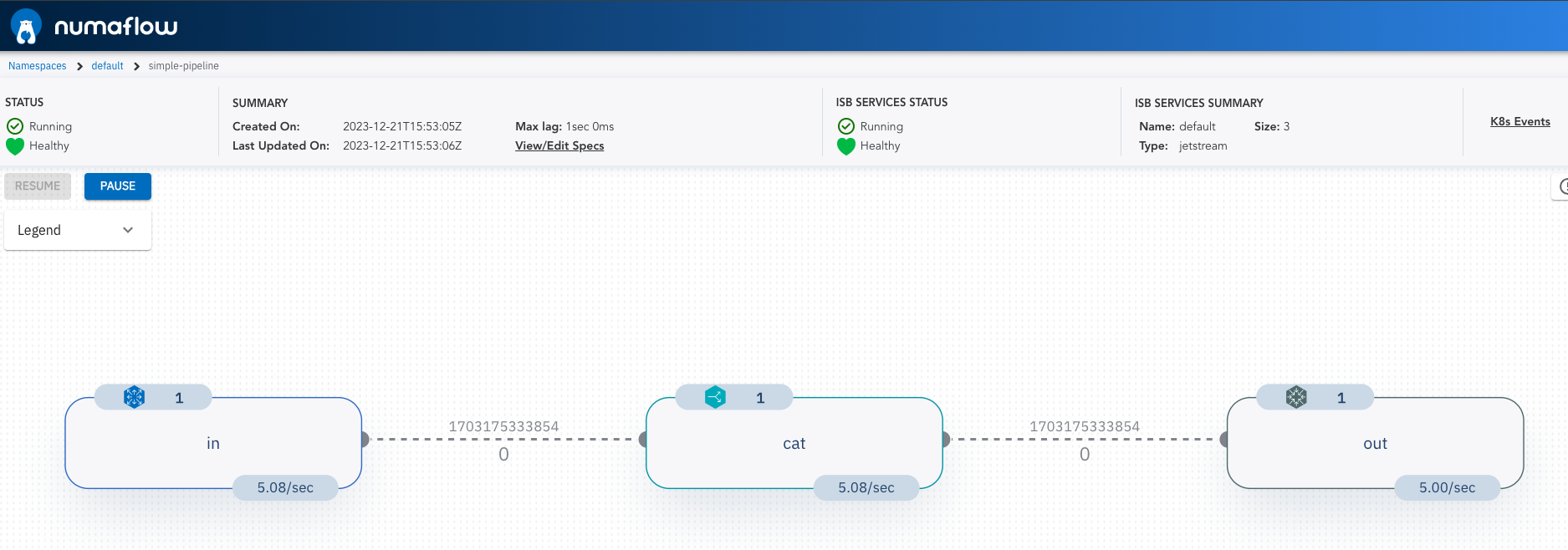
Web UI から yaml を編集してリソースを作成したり、編集、削除できる。 試しにinの部分の RPS を変更すると scale out して pod が増えることを確認できた。